This post follows from my previous post about RAGs (steps 1, 2, and 3) which can be found here: https://techstuff.leighonline.net/2024/04/30/creating-a-vector-database-for-rag-using-chroma-db-langchain-gpt4all-and-python/
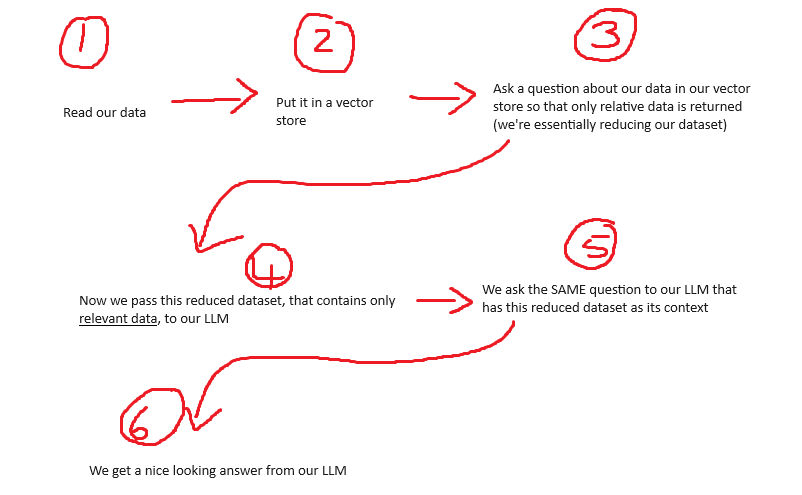
In this post we will spin up the LMStudio server and use Langchain to chat to a Lambda3 model. We are going to focus on steps 4, 5, and 6 in our simplified RAG flow:
Some good reading
LMStudio is code and parameter compatible with OpenAI to make development easier for those already familiar with OpenAI’s ChatGPT
| What | Where |
| LMStudio local server docs | https://lmstudio.ai/docs/local-server |
| OpenAI API reference | https://platform.openai.com/docs/api-reference/audio |
| RunnablePassthrough Langchain | https://api.python.langchain.com/en/latest/runnables/langchain_core.runnables.passthrough.RunnablePassthrough.html |
| StrOutputParser Langchain | https://www.restack.io/docs/langchain-knowledge-langchain-stroutputparser-guide |
LMStudio
Download LMStudio, download the Lambda3 model, and start the server
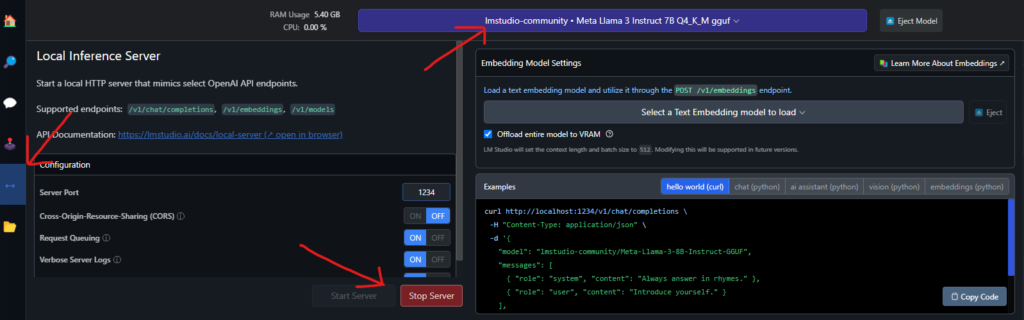
Once the server is started, you will see this in the server logs
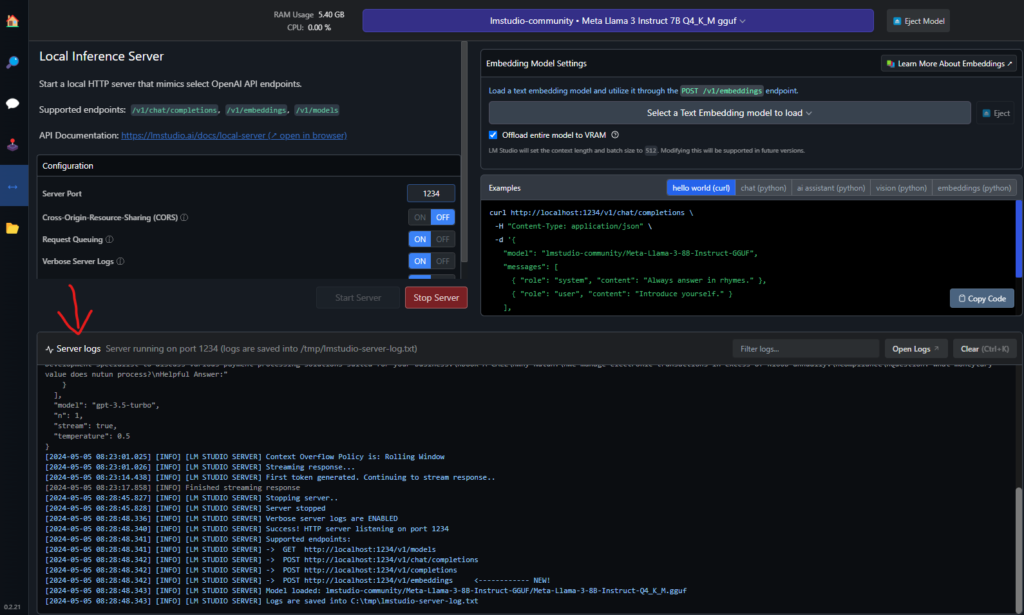
In the “Useful URL” table above, have a look at “LMStudio local server docs” to see what endpoint are available.
Chatting with our model in LMStudio
You can chat to your model in LMStudio using native REST as well, but we will use Langchain for this.
I will use the “GPT4all” RAG example from my post linked above, and then just add the following code to it.
Lets import some langchain modules
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParserBecause LMStudio is compatible with ChatGPT, we can use the “chatOpenAI” module.
Define a function to format the data our vectorstore will return
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)We will come back to this function in a moment.
Lets define our template message
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""We will discuss how “question” and “context” are passed through in a moment.
Now lets define our prompt object and our LLM object
custom_rag_prompt = PromptTemplate.from_template(template)
llm = ChatOpenAI(temperature=0.5, base_url="http://localhost:1234/v1", api_key="lmstudio")Lets now define our chain and discuss what this does
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| custom_rag_prompt
| llm
| StrOutputParser()
)The pipe character (|) is essentially used to “chain” together a bunch of functions. Lets break this down:

In 1 above, we create our object that contains our “retriever” which is our “vectorstore.as_retriever” object from our previous post about RAGs, and we pass this data to our “format_docs” function as input so that it is nicely formatted. This output is then assigned to the “context” key.
We then assign a “RunnablePassthrough()” object as our “question” which you can read more about (link in the table above).
In 2, we then assign the object from 1 to our “custom_rag_prompt” object, which contains our “template” text. Remember our template text had a placeholder for “context” and “question“. So essentially, our context and question will now get injected into our template.
In 3, we now pass everything from 1 and 2 to our “ChatOpenAI” object.
And finally, we use Langchains StrOutputParser to format our output properly.
You dont have to use chaining like this, it is just a neat way to create data, and pass it on to a function.
Let print out our answer
for chunk in rag_chain.stream(our_query):
print(chunk, end="", flush=True)So in the section above we passed our template, our context (the data our vector store returned based on our question), and our question again to our LLM. So here our LLM will just nicely format the output.
And here is the output
