In its simplest form, a RAG consists of these steps. We will focus on step 1, 2, and 3 in this post:
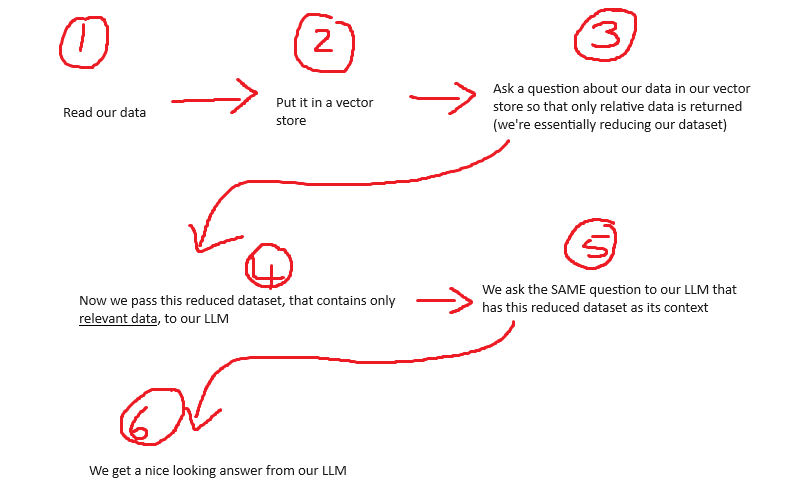
In our follow up post we will perform step 4, 5, and 6:
https://techstuff.leighonline.net/2024/05/05/local-chatgpt-using-lmstudio-lanchain-and-our-rag-data/
Lets start at the beginning
In this post we will look at 3 different ways to create a vector database using Chroma DB, and then we will query that vector database and get our results.
Method 1: We will create a vector database and then search it using a scentence transformer. We will use only ChromaDB, nothing from Langchain. We will also not create any embeddings beforehand. Here we will insert records based on some preformatted text.
Method 2: We will create a vector database and then search it using a scentence transformer, but, we will use some features from Langchain. We will create a vector database and store the embeddings beforehand. Here we will use a Text Splitter; very useful for long pieces of text.
Method 3: The same as method 2, but we will use GPT4all.
Take note: All examples will use the “all-MiniLM-L6-v2” model. This is GPT4All’s default model if you don’t specify anything else.
Some good reading
| What | Where |
| Visiaulize text chunks | https://chunkviz.up.railway.app/ |
| GPT4All GPU processing | https://docs.gpt4all.io/gpt4all_python_embedding.html#quickstart |
| LMStudio Server | https://lmstudio.ai/docs/local-server |
Method 1: Scentence Transformer using only ChromaDB
This method is useful where data changes very quickly so there is no time to compute the embeddings beforehand.
Lets do some pip installs first
pip install -U sentence-transformers
pip install -U chromadbWe need to define our imports. It is not a whole lot
import chromadb
from chromadb.utils import embedding_functionsNext, we need to define some variables
#setup variables
chroma_db_persist = 'c:/tmp/mytestChroma3/' #chroma will create the folders if they do not exist
chroma_collection_name = "my_lmstudio_test"
embed_model = "all-MiniLM-L6-v2"Then we need to create some objects
#setup objects
embedding_func = embedding_functions.SentenceTransformerEmbeddingFunction(model_name=embed_model)
chroma_client = chromadb.PersistentClient(path=chroma_db_persist)
chroma_collection = chroma_client.get_or_create_collection(name=chroma_collection_name, embedding_function=embedding_func)A quick Google search for all-MiniLM-L6-v2 takes us onto Huggingface, where we can see it is a 384 dimension transformer.
Lets read in some text
#read our file
#I split the data on ***
with open("mytext2.txt", "r") as mytext:
content = mytext.read()
content_list = content.split('***')This text file contains information about a random company website and what that company does. I split each of the things they claim to do with “***”. So each split will be a row in my collection.
You can use the company you work for, or a friend’s website, and just copy the text into a file for this example.
Essentially, “content_list” will become the records in our collection (our vector store).
Lets add these records to our vector store
chroma_collection.add(
documents = content_list,
ids = [f"id{i}" for i in range(len(content_list))]
#metadatas = [list of dicts] not needed
)What we’re doing is we are adding our “content_list” to our collection, and then just adding the IDs. The IDs can be anything, but it must be unique for each record. See it as a primary key in SQL. So here we are adding the rows into our collection, and the collection can be seen as a table in SQL.
Another field (column) that we can add is “embeddings”, but you don’t have to. If you dont provide these embeddings, every time you search your collection, Chroma will create them. See this screenshot below.

We are using the “SentenceTransformerEmbeddingFunction” which we defined above.
There is a lot you can do with Chroma collections. You can read more here:
| What | Where |
| Chroma Collections | https://docs.trychroma.com/reference/Collection |
| Chroma User Guide | https://docs.trychroma.com/usage-guide |
And now we can pass a search qeuery
query_results = chroma_collection.query(query_texts=["how much do we anually process"], n_results=3)
print(query_results.keys())
print(query_results["documents"])
print(query_results["ids"])
print(query_results["distances"])And here we can see the results to my question: “how much do we anually process“

My list that I read into my collection had 7 items, but where we can see that only id4, id1, and id7 was returned. This is because the other items (rows in our collection) has nothing to do with processing, money, etc.
A lower distance typically means a better match.
Method 2: Scentence Transformer using Langchain and creating the embeddings beforehand
This method is useful where data remains generally static, so you can compute the embeddings, store them, and then just reload the existing DB every time without having to re-compute them.
Lets start with the pip installs first
pip install -U langchain-community
pip install -U langchain-chroma
pip install -U langchain-text-splittersLets define our variables
#setup variables
chroma_db_persist = 'c:/tmp/mytestChroma3_1/' #chroma will create the folders if they do not existAnd lets create some objects
#setup objects
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=80, add_start_index=True)
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")Here we will use a Text Splitter from Langchain. This is very useful when you have a large piece of text that you want to break up into smaller chunks.
Now lets read our text
#read the text
loader = TextLoader("./mytext.txt")
docs = loader.load()
all_splits = text_splitter.split_documents(docs)This is again just a super long piece of text, like an article from Wikipedia that I copied into a text file. But here we are splitting the text using our defined Text Splitter.
Lets create our vector store
#create the vectorstore
vectorstore = Chroma.from_documents(documents=all_splits, persist_directory=chroma_db_persist, embedding=embedding_function)Here we create a vector store using our splitted text, and we tell it to use our embedding function which again is a “SentenceTransformerEmbeddings”
Now lets query our vector store and look at the results
query = "what moneytary value does nutun process?"
retrieved_docs = vectorstore.similarity_search(query)
# print results
print(len(retrieved_docs))
print(retrieved_docs[0].page_content)
And here is the results of my question “what moneytary value does nutun process?“

We can visualize our chunks using https://chunkviz.up.railway.app/

Method 3: The same as method 2, but using GPT4All
We start off again by defining our imports (no new pip install needed here)
from langchain_community.embeddings import GPT4AllEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import ChromaThen we define our variables and our objects. The only difference here is that we are using GPT4All as our embedding
#setup variables
chroma_db_persist = 'c:/tmp/mytestChroma3_1/' #chroma will create the folders if they do not exist
#setup objects
gpt4all_embd = GPT4AllEmbeddings()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=80, add_start_index=True)Then we read our text and create the vector store
#read the text
loader = TextLoader("./mytext.txt")
docs = loader.load()
all_splits = text_splitter.split_documents(docs)
#create the vectorstore
vectorstore = Chroma.from_documents(documents=all_splits, persist_directory=chroma_db_persist, embedding=gpt4all_embd)Lets query our vector store
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})
retrieved_docs = retriever.invoke("what moneytary value does nutun process?")Here we can see we are still using “similarity” search, but we are just using different syntax, and we are saying we only want the first 6 results from our query.
And the results will look the same as in method 2
#see the results
print(len(retrieved_docs))
print(retrieved_docs[0].page_content)
